Language-Guided Cognitive Planning with Video Prediction
Vector Institute | May 2021 - Apr 2022 | Research, team of Three
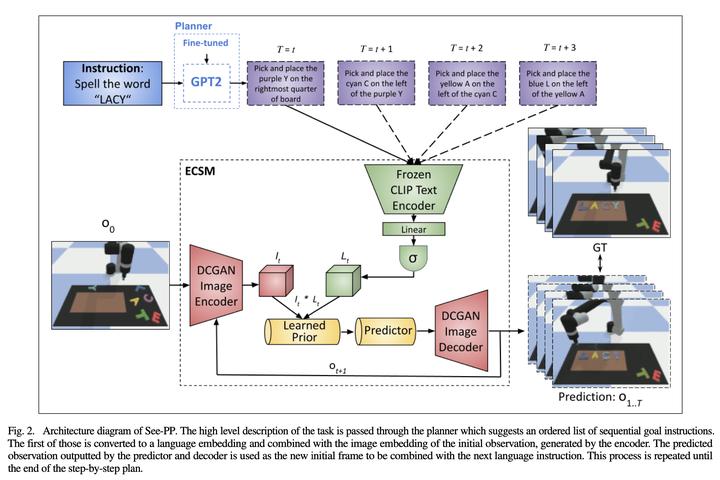
We proposed a novel architecture to tackle computational cognitive planning as a video prediction problem, given an initial visual observation and a natural language task description. The architecture was broken down into two submodules: high-level planning of actions by a transformer model, and cognitive grounding of the planned actions by an extended video generation network.
My contributions:
-
Experimented with the high-level planning submodule and solved the issues such as unstable training results by scheduling meetings with the author and reporting progress to other teammates timely
-
Improved the generalizability of the grounding submodule to unseen objects, by adding a language model as the text encoder (two different approaches experimented: BERT model and text encoder in CLIP)
-
Discussed and proposed different real dataset ideas, recorded several possible real datasets including ‘stack plastic dinnerware’, ‘assembly kits’ and ‘spelling words’, and examined their feasibility
-
Implemented a stochastic CLVER dataset on Isaac Sim, connected it with OMPL motion planner, tested with different physics solvers such as ROS, Pybullet, and motion planners including MoveIt and Riemannian Motion Policy
-
Experimented with and conducted plenty of research for additional datasets including ‘BEHAVIOR’ and ‘EPIC-KITCHENS’ datasets. Implemented a simulation dataset of a robot arm performing spelling of various words on a board
-
Implemented the grounding submodule with different encoder-decoder architectures (DCGAN, U-Net, or CrevNet), solved the problems during training such as blurred image generations and slow progress by hyperparameter tuning
-
Implemented the evaluation with different performance metrics including SSIM, LPIPS, PVQA, and OCR metric, demonstrated significant improvements by comparing to video generation baselines, and better grounding generalization to unseen objects